21.2 ID3 (Iterative Dichotomiser 3)

ID3 (Iterative Dichotomiser 3) is a popular algorithm used to construct a decision tree for classification problems.
It selects the best attribute for splitting the data based on Information Gain, which is calculated using Entropy.
The main goal of ID3 is to create a tree that classifies data with maximum purity at each node.
What ID3 Stands For
ID3 stands for Iterative Dichotomiser 3.
Key Idea of ID3
ID3 chooses the attribute that reduces entropy the most and makes the data as pure as possible after splitting.
Measures Used in ID3
ID3 uses the following measures:
Entropy – to measure impurity
Information Gain – to select the best attribute for splitting
(a) Entropy
Entropy measures the impurity or randomness in the dataset.
Formula:
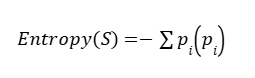
Entropy = 0 → Pure node
Entropy is maximum → Highly impure node
6. Information Gain Formula
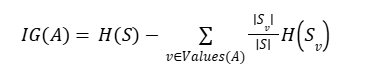
Where:
IG(S, A)
→ Information Gain of attribute A on dataset S
S
→ Complete dataset (parent/root node)
A
→ Attribute (feature) used for splitting
H(S)
→ Entropy of the dataset before splitting
Values(A)
→ All possible values of attribute A
v
→ A specific value of attribute A
Sᵥ
→ Subset of dataset S where attribute A = v
|S|
→ Total number of samples in dataset S
|Sᵥ|
→ Number of samples in subset Sᵥ
|Sᵥ| / |S|
→ Weight of subset Sᵥ
H(Sᵥ)
→ Entropy of subset Sᵥ after splitting
∑ (summation)
→ Sum of weighted entropies of all subsets
Algorithm Steps of ID3
ID3 Algorithm Steps
Calculate the entropy of the dataset.
For each attribute, calculate the Information Gain.
Select the attribute with the highest Information Gain as the root node.
Split the dataset based on the selected attribute.
Repeat the process recursively for each child node.
Stop when:
All samples belong to the same class, or
No attributes are left for splitting.
Characteristics of ID3
Suitable for multiclass classification
Uses Entropy & Information Gain
Mainly used for classification
Works best with categorical data
Can split a node into more than two branches
Pure and Impure Split using Entropy (with Example)
Pure and Impure Split using Entropy (with
Example)
Imagine separating apples and oranges.
If one basket has only apples, the separation is perfect.
If another basket has apples and oranges mixed, the separation is confusing.
Decision trees face the same situation.
Entropy helps the tree decide whether a split is clean (pure) or messy (impure).
Based on entropy values, splits are classified as pure or impure.
Definition of Pure and Impure Split
Pure Split
→ All samples belong to the same class
→ Entropy = 0
Impure Split
→ Samples belong to more than one class
→ Entropy > 0
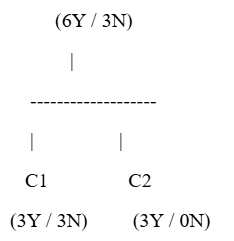
Suppose, given data is
Feature

Overall Class Distribution
Feature-wise Split (as needed for entropy)
Feature
Total samples = 9
Yes (Y) = 6
No (N) = 3
Step 1: Entropy of Root Node (Before Split)
Formula of Entropy

Since entropy > 0, the node is IMPURE.
Step 2: Split on Feature → C1 and C2
Split 1: Node C1
From your notes:
Y = 3
N = 3
Total = 6
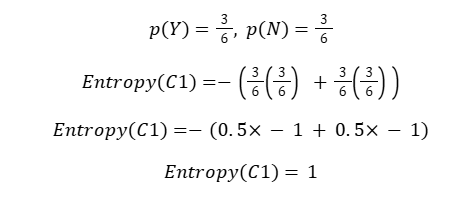
Maximum entropy → Completely IMPURE split
Split 2: Node C2
From your notes:
Y = 3
N = 0
Total = 3
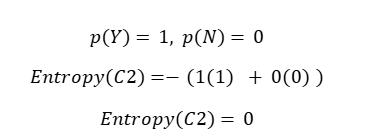
Entropy = 0 → PURE node
Step 3: Interpretation (Pure vs Impure)
Pure Split
All samples belong to one class only
Entropy = 0
No further splitting needed
In this example:
C2 is a PURE split
Impure Split
Samples belong to multiple classes
Entropy > 0
Further splitting required
In this example:
Root node (0.918) → Impure
C1 node (1) → Highly impure
Step 4: Summary Table

Thus, ID3 constructs a decision tree by selecting attributes that provide maximum
information gain, resulting in an efficient and interpretable classification model.
Key Points
Pure node → Entropy = 0
Impure node → Entropy > 0
Decision trees try to create pure child nodes
ID3 uses entropy and information gain
Best split is the one that reduces impurity the most




